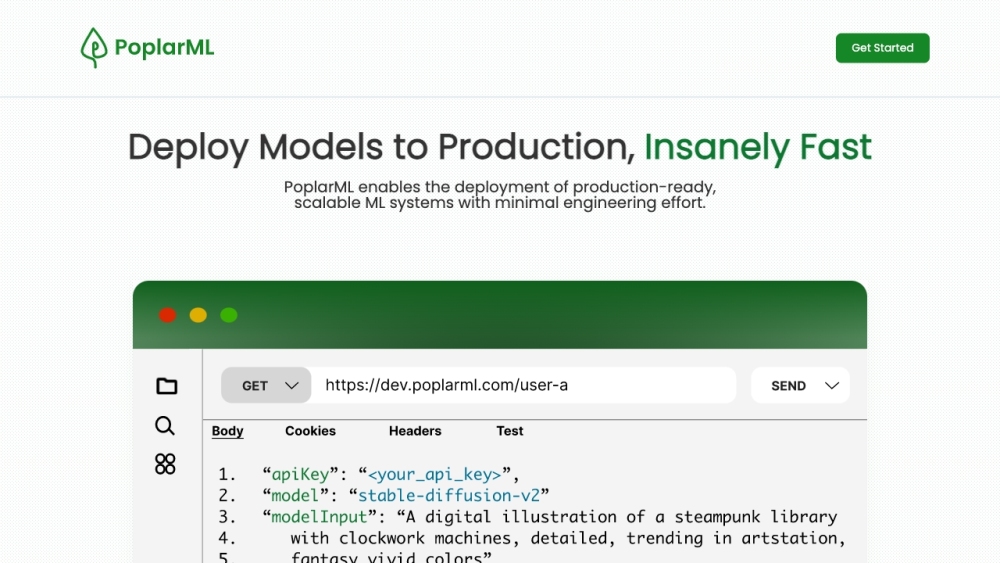
PoplarML - Deploy Models to Production
Deploy machine learning models easily using PoplarML, which supports widely-used frameworks and provides real-time inference.
Alternative Tools
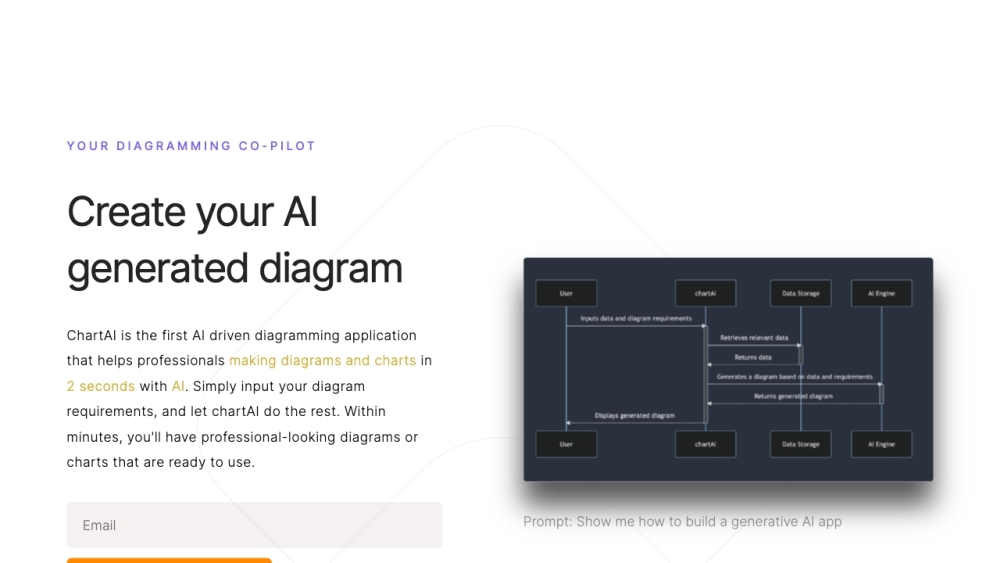
ChartAI
ChartAI utilizes ChatGPT technology to assist users in generating and interpreting charts and diagrams.
Image
Productivity

Gooey.AI
Gooey.AI makes AI easy with a simple coding setup, using the newest models to turn ideas into reality.
Text&Writing
Image
Pixelicious
Transform your images into amazing retro-style pixel art creations using Pixelicious.
Image
Marketing