
Dioptra
Dioptra is an open-source platform designed to handle data curation and management tasks specifically in the fields of computer vision and natural language processing.
Alternative Tools

CyberRiskAI
CyberRiskAI is a powerful tool that uses Artificial Intelligence to help businesses evaluate and reduce their cybersecurity risks effectively.
Text&Writing
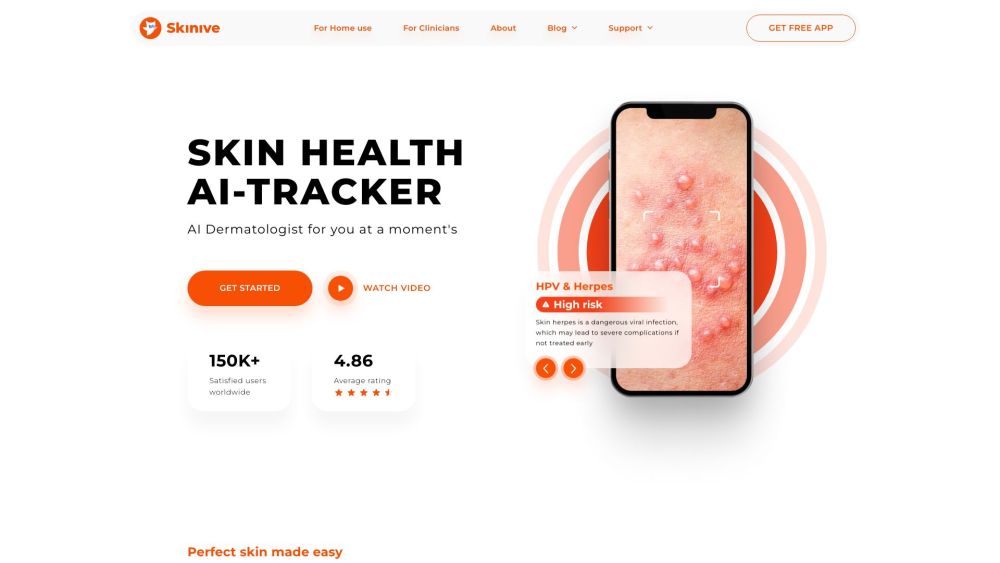
Skinive: SkinCare & Health App
Skinive, a cutting-edge skincare application powered by Artificial Intelligence, carefully examines the skin and provides tailored advice for improved skincare.
Text&Writing
Marketing